Новости центра
Фильтр по:

3 ноября 2023 г. 16:27
Высокотехнологичные рабочие места: Алексей Белошицкий принял участие в заседании круглого стола в Совете Федерации
Комитет Совета Федерации по экономической политике провел круглый стол на тему «Меры экономического стимулирования создания новых высокотехнологичных рабочих мест». Одним из участников данного мероприятия стал исполнительный директор Центра НТИ по больши…

25 октября 2023 г. 12:10
Учёные Центра НТИ создали систему для проверки защищённости ИИ-систем от кибератак
Учёные Центра хранения и анализа больших данных МГУ разработали сервис для проверки устойчивости ИИ-решений к кибератакам.

13 октября 2023 г. 16:42
Закрытая встреча АгроИнвест Клуба от Россельхозбанка и Сколково
25 октября 2023 года в Москве состоится мероприятие от Россельхозбанка и закрытого АгроИнвест Клуба, посвященное поиску перспективных проектов и направлений в агротехнологиях, нетворкингу профессионального сообщества и поддержке новых технологий, способн…

20 сентября 2023 г. 13:07
Специалисты Московского урбанистического форума провели исследование городской среды в крупнейших мегаполисах мира
Эксперты Аналитического центра АНО «Московский урбанистический форум» совместно с Фондом Росконгресс и МГУ имени М.В.Ломоносова подготовили аналитический отчет, в котором раскрываются вопросы развития городов стран БРИКС. Исследование было проведено спец…

25 августа 2023 г. 14:12
VI Расширенное заседание технического комитета по стандартизации ТК 164 «Искусственный интеллект»
Представитель ЦК НТИ, ответственный секретарь Подкомитета 02 «Данные» Технического комитета по стандартизации 164 «Искусственный интеллект», к.ю.н. Сергей Афанасьев принял участие в VI Расширенном заседании Технического комитета по стандартизации ТК 164 …

Представители ЦК НТИ по большим данным МГУ рассказали о разработках в сфере предиктивной аналитики технических систем и аналитики потоков
26 ноября 2020 г. 11:37
20 ноября в онлайн-режиме состоялся круглый стол «Современные методы анализа данных» с участием экспертов Центра компетенций НТИ по большим данным МГУ, Высшей школы современных социальных наук МГУ, а также представителей компаний «Инвитро», HeadHunter и Elsevier.
Организаторами мероприятия выступили МГУ имени М.В. Ломоносова, Клуб директоров по науке и инновациям (iR&Dclub) и Центр компетенций НТИ по большим данным на базе МГУ. В рамках встречи участники обсудили актуальные вопросы совершенствования методологии и инструментария аналитики в ответ на новые вызовы, инновационные технологические решения и опыт использования технологий анализа больших данных в корпоративном секторе.
Круглый стол открыли Алексей Филимонов, исполнительный директор Клуба директоров по науке и инновациям (iR&Dclub), и Олег Карасев, проректор МГУ, руководитель направления коммерциализации Центра компетенций НТИ по большим данным.
«Смысл наших сессий – рассказать о прорывных и интересных новациях, которые потенциально применимы в бизнесе», – поделился Алексей Филимонов.
Олег Карасев отметил, что круглый стол, посвященный современным методам анализа данных, проводится в МГУ уже в пятый раз: «За последние годы проведение такого рода мероприятий стало традицией Московского университета».
Спикер подчеркнул актуальность проведения круглого стола: «Мы видим, как глобальные вызовы последних лет выступили драйверами развития новых секторов экономики и технологий, на которых они основаны. Все эти тенденции наглядно проявляются в России. За последние пять лет, по некоторым оценкам, вклад цифровой экономики в макроэкономические показатели нашей страны увеличился более чем вдвое. События последнего года в значительной степени этому способствовали. Только за первый квартал 2020 года спрос на услуги стационарного интернета вырос примерно на треть, а мобильного – на 15%. На отдельные сектора (например, цифровое образование) это повлияло революционным образом».
По словам Олега Карасева, многие приоритеты в сфере цифровой экономики сегодня установлены государственными стратегическими документами. Так, в число приоритетных технологий входят технологии информационной безопасности, искусственного интеллекта, больших данных, блокчейна, новых средств коммуникации, робототехники, облачных вычислений.
«Московский университет ориентирует исследовательскую деятельность на развитие и поддержку таких областей знания. В частности, за последние годы в структуре университета был создан целый ряд специализированных исследовательских центров, работающих в данных направлениях. В их числе Центры Национальной технологической инициативы, которых в МГУ создано два – в области квантовых технологий и технологий хранения и анализа больших данных… По инициативе ректора Московского университета в партнерстве с ведущими институтами Академии наук был создан математический центр мирового уровня. Сейчас завершается первый год его активного развития. Его миссией является получение фундаментальных научных результатов в разных областях вычислительной математики, теоретической информатики, высокопроизводительных вычислений», – обратил внимание спикер.
Александр Гребенюк, заместитель директора по научной работе Высшей школы современных социальных наук МГУ, выступил с докладом «Специфика Big Data электронных социальных сетей». Спикер обозначил разницу между понятием «цифровизация», производной от которой является цифровой профиль, и понятием «виртуализация», которой соответствует аккаунт социальной сети. «Цифровизация – по сути, это оцифровка объективной реальности. Цифровой профиль, который появляется в результате цифровизации, содержит реальные данные о реальных вещах. Мы что-то купили – оставили цифровой след, куда-то переместились – оставили цифровой след, в поисковой строке вбили запрос – оставили цифровой след. Поэтому цифровой профиль – это суммарный объем объективной информации о том, что в реальности было», – отметил Александр Гребенюк.
Виртуализация, в рамках которой тоже формируются колоссальные массивы больших социальных данных, отличается от цифровизации «субъективностью» данных. К таковым относятся данные о сообщениях, потребляемом контенте, лайках, репостах, состоянии в группах и т. д. аккаунта социальной сети. Виртуальная реальность в настоящее время является искусственной социальной средой взаимодействия аккаунтов, которые представляют собой учетные записи человека в социальной сети, определенные виртуальные страницы, цифровые пространства, следует из презентации Александра Гребенюка. В сети формируется виртуальная идентичность. При этом, по словам спикера, социологи наблюдают дуализм позиционирования: как правило, существует большая разница между тем, как человек хочет выглядеть в сети, и тем, кем он на самом деле является.
Законы и закономерности взаимовлияния социальных процессов, протекающих в виртуальной реальности и физическом мире, изучает цифровая социология. Она обладает междисциплинарным набором методов. К ним относятся методы прикладной лингвистики; методы социальной психологии (необходимы для «профайлинга» конкретного аккаунта и определения психоэмоционального состояния различных социальных групп); методы работы с большими данными сетевой активности личности; методы графов (изучение графов связи); статистические методы; методы распознавания изображений и видео, размещенных на странице пользователя.
Директор по стратегическому развитию и инновациям «Инвитро» Дмитрий Фадин рассказал о вызовах, которые, по его мнению, сдерживают широкое применение больших данных в медицине. «Главная проблема, которую мы..., как мировое сообщество, работающее с медицинскими данными, решаем, – это проблема, которая называется GIGO (garbage in – garbage out). Несмотря на то, что каждая единица данных, которая присутствует у медицинских организаций, очень строго выверена, верифицирована, она выработана для очень конкретного, четкого и понятного применения… Применить эти данные на пользу людям в виде большого объема данных не очень пока получается», – считает спикер.
«Хорошей моделью сейчас в медицине является то, когда вы проверяете искусственным интеллектом за человеком, а не наоборот. То есть сначала человек независимо смотрит на снимок. Потом на него смотрит искусственный интеллект, говорит: “Слушай, а ты не пропустил ли здесь вот это?” После этого на снимок смотрит еще несколько человек. Это серьезно повышает трудоемкость процесса, но зато повышает качество. Поэтому я был бы крайне аккуратен с тем, как эти [медицинские] данные используются, и каждый раз очень аккуратно верифицировал бы модель, во-первых, с задачами, во-вторых, с качеством исходных данных», – отметил Дмитрий Фадин.
Илья Муха, руководитель разработки программного обеспечения Центра компетенций НТИ большим данным на базе МГУ, выступил с докладом об одном из проектов организации – «Предиктивная аналитика технических систем». В рамках реализации данного проекта на базе Центра создан консорциум, в который вошли ГК «Ракурс», ГК «Ланит», Санкт-Петербургский политехнический университет Петра Великого, Московский физико-технический институт и Уральский федеральный университет.
Разрабатываемый продукт представляет собой программный комплекс и набор моделей по предиктивной аналитике для прогнозирования отказов оборудования и повышения эффективности производства. Аналитическая платформа способна снижать число простоев и сбоев при производстве, предотвращать отказы оборудования и повышать качество готовой продукции. Потенциальными потребителями разработки являются производственные и добывающие компании в нефтегазовой, металлургической, энергетической и других отраслях. Предусмотрена возможность кастомизации программного комплекса, то есть его настройки с учетом потребностей конкретной компании.
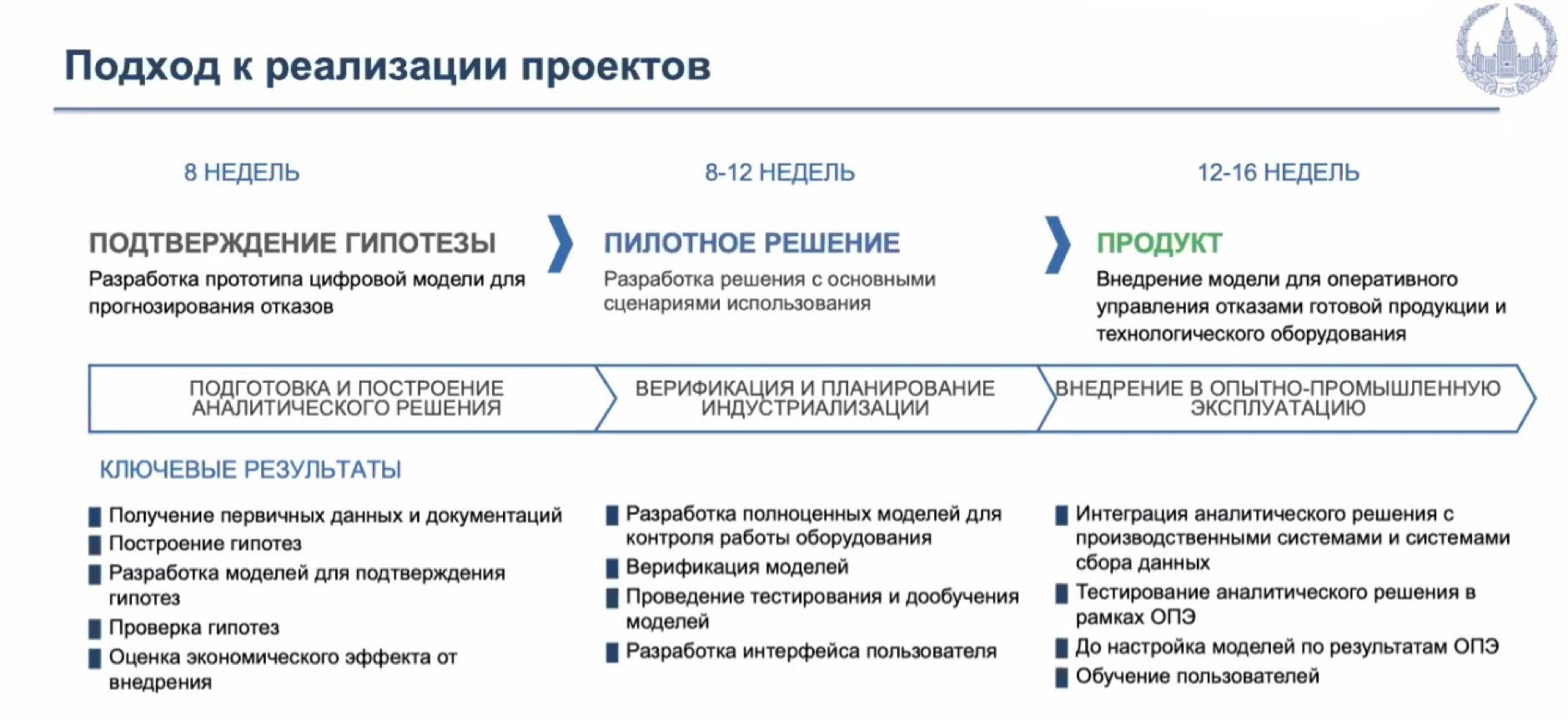
«Две идеи, которые мы используем. Одна, наверное, более или менее всем знакома: берутся исторические эксплуатационные данные, к ним – журналы данных о работе оборудования, о различных простоях; данные размечаются; строятся различные модели. В идеале система должна уже говорить, когда и что будет выходить из строя, но зачастую это не так. Во-первых, случается, что данные не размечены, не фиксируются либо их не хватает. Еще одна из проблем: такие методы прогнозной аналитики позволяют обезопаситься только от тех проблем, которые случались… Поэтому огромным плюсом является применение такой популярной сейчас тематики, как цифровое моделирование, цифровой двойник… Но она требует больших вычислительных ресурсов, поэтому мы стараемся исследовать такой новый подход, как использование нейросетей для решения дифференциальных уравнений, когда модель решается не в трехмерном формате, а разбивается на двумерные задачи и впоследствии решается с помощью нейросетей, что позволяет сократить количество использованных вычислительных ресурсов», – рассказал Илья Муха. Результатом работы является графический пользовательский интерфейс, воспользоваться которым могут сотрудники, у которых нет специальных знаний в области анализа данных.
Командой Центра компетенций НТИ по большим данным на базе МГУ уже реализованы проекты по предиктивной аналитике для ПАО «Северсталь»: проанализировано более 150 различных параметров и разработана модель для раннего оповещения оператора. Определено, что экономическая выгода от внедрения моделей может составлять до 60-70 млн рублей в год на одном типе оборудования.
Команда проекта также занимается предиктивной аналитикой на базе спектроскопии сточных вод. Создается специальный прибор на основе спектрометра, способный определять неполадки в работе предприятия путем идентификации в сточных водах веществ, которые не должны там присутствовать. По словам Ильи Мухи, каждое загрязняющее вещество обладает специфическим спектром поглощения. Разработка позволяет выявлять превышения предельно допустимой концентрации вещества по оптическому спектру с помощью машинного обучения. «Разрабатываем сейчас такой прибор, который с помощью спектроскопии, во-первых, может вытягивать различные спектры по различным загрязняющим веществам, во-вторых, используя облачную платформу, этот спектр обрабатывать, в-третьих, сигнализировать о присутствии тех или иных веществ», – пояснил Илья Муха.
Борис Вольфсон, директор по развитию HeadHunter, на примере компании рассказал об использовании машинного обучения в системах поиска работы. «Мы занимаемся тем, что для работодателей находим подходящих соискателей. Вот этот “матчинг” и делают системы искусственного интеллекта», – поделился спикер.
Роман Смирнов, ведущий специалист Центра компетенций НТИ по большим данным на базе МГУ, выступил с докладом «Данные WiFi и предиктивной аналитики передвижения человека на определенной территории – современные подходы в условиях ограничений». По словам спикера, одной из основных целей трекинга на основе WiFi является таргетинг рекламы. Ее можно настроить, зная MAC-адрес устройства пользователя. При этом архитектура WiFi-сниффинга сегодня широко развита (в торговых центрах, кафе и т. д.). Однако ее эффективность стремительно снижается из-за того, что производители смартфонов предпочитают скрывать реальные MAC-адреса, идентифицирующие устройства. С учетом того, что разные смартфоны отправляют разное количество сигналов, анализ потоков затруднен.
Преодолением данного барьера занимается команда Центра компетенций НТИ по большим данным на базе МГУ. По словам Романа Смирнова, знания закономерностей сигналов разных смартфонов и дифференциация по физическим характеристикам антенн позволяют определять плотность людей, а не сигналов в пространстве. «Определив модель и поняв, в каком примерно режиме работает телефон, мы можем ожидать, когда от него будет следующий сигнал, и, таким образом, более точно понимать, сколько человек скапливается в той или иной точке», – отметил спикер.
Разработка направлена на аналитику потоков (определение зон основной проходимости), а также предиктивную аналитику потоков (прогнозирование, когда и где образуется скопление людей). При этом не требуется установка дополнительных датчиков, помимо уже имеющихся WiFi-снифферов.
Роман Смирнов охарактеризовал текущую стадию реализации проекта: «Собрана физическая инфраструктура, аналогичная той, что стоит в тех же торговых площадках, разработана концепция программного обеспечения, ведется поиск площадки для внедрения и непосредственного тестирования этой разработки».
Глобальный коммерческий директор Elsevier Джейб Уилсон представил сервис «Данные-как-услуга (DaaS)», направленный на создание аналитических инструментов поддержки эффективных НИОКР и внедрения коммерчески успешных инноваций. «Сервис DaaS обеспечивает огромный объем надежного высококачественного машиночитаемого контента и данных для всей команды НИОКР, стимулируя взаимодействие между лабораторными исследованиями, in silico и наукой о данных», – следует из презентации спикера.