Новости центра
Фильтр по:

3 ноября 2023 г. 16:27
Высокотехнологичные рабочие места: Алексей Белошицкий принял участие в заседании круглого стола в Совете Федерации
Комитет Совета Федерации по экономической политике провел круглый стол на тему «Меры экономического стимулирования создания новых высокотехнологичных рабочих мест». Одним из участников данного мероприятия стал исполнительный директор Центра НТИ по больши…

25 октября 2023 г. 12:10
Учёные Центра НТИ создали систему для проверки защищённости ИИ-систем от кибератак
Учёные Центра хранения и анализа больших данных МГУ разработали сервис для проверки устойчивости ИИ-решений к кибератакам.

13 октября 2023 г. 16:42
Закрытая встреча АгроИнвест Клуба от Россельхозбанка и Сколково
25 октября 2023 года в Москве состоится мероприятие от Россельхозбанка и закрытого АгроИнвест Клуба, посвященное поиску перспективных проектов и направлений в агротехнологиях, нетворкингу профессионального сообщества и поддержке новых технологий, способн…

20 сентября 2023 г. 13:07
Специалисты Московского урбанистического форума провели исследование городской среды в крупнейших мегаполисах мира
Эксперты Аналитического центра АНО «Московский урбанистический форум» совместно с Фондом Росконгресс и МГУ имени М.В.Ломоносова подготовили аналитический отчет, в котором раскрываются вопросы развития городов стран БРИКС. Исследование было проведено спец…

25 августа 2023 г. 14:12
VI Расширенное заседание технического комитета по стандартизации ТК 164 «Искусственный интеллект»
Представитель ЦК НТИ, ответственный секретарь Подкомитета 02 «Данные» Технического комитета по стандартизации 164 «Искусственный интеллект», к.ю.н. Сергей Афанасьев принял участие в VI Расширенном заседании Технического комитета по стандартизации ТК 164 …
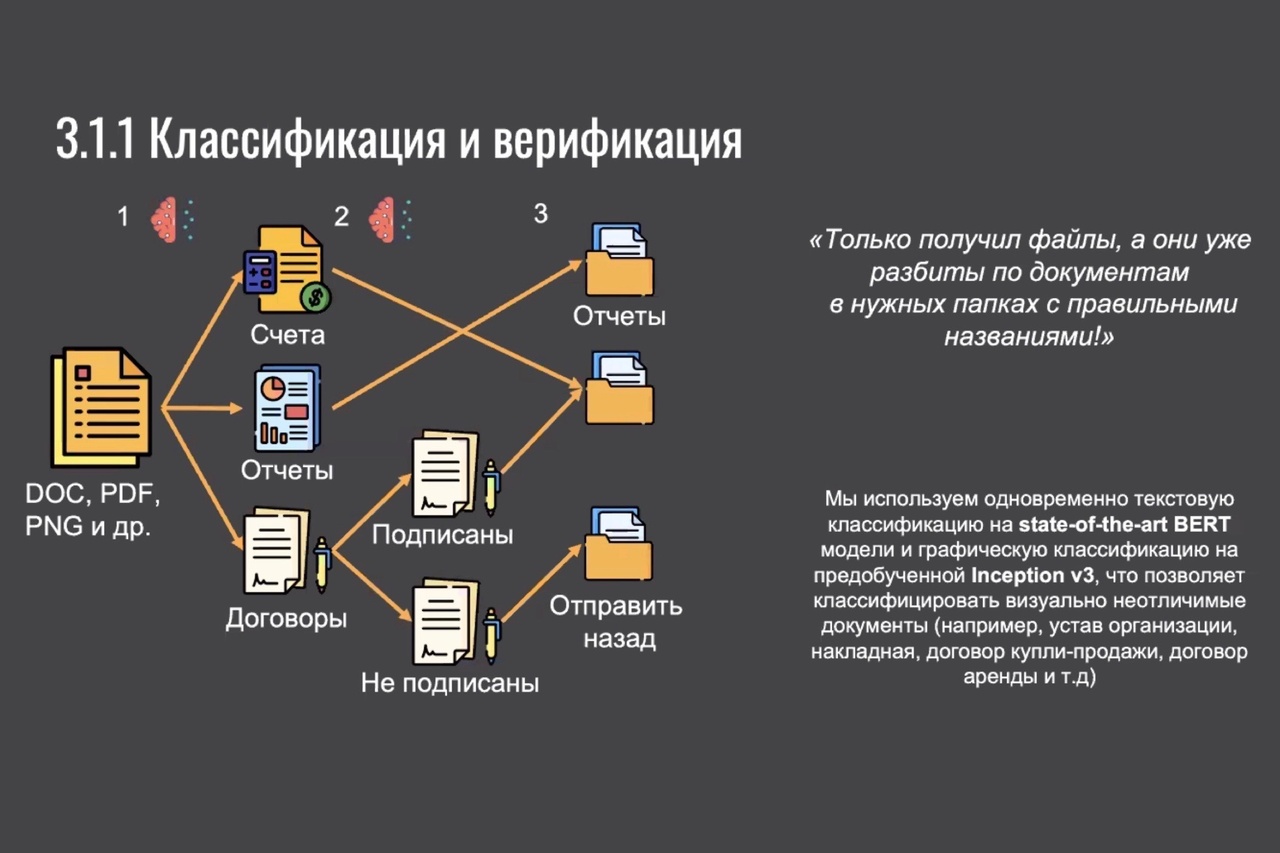
В Центре НТИ по большим данным МГУ разрабатываются NLP-решения по распознаванию документов
23 апреля 2021 г. 10:26
21 апреля в рамках ежегодной научной конференции «Ломоносовские чтения 2021» состоялся круглый стол «Методы анализа данных: перспективы, возможности и успешные практики». На мероприятии выступили специалисты Центра компетенций НТИ по технологиям хранения и анализа больших данных на базе МГУ, рассказав о достижениях Центра в области распознавания документов и практическом применении этих разработок.
Организаторами мероприятия выступили Центр компетенций НТИ МГУ и ФГБУ «Связист» Минцифры России. Модератором мероприятия стал Егор Шитов, руководитель направления технологического консалтинга Центра компетенций НТИ МГУ.
Антон Привезенцев, директор ФГБУ «Связист» Минцифры России, приветствуя участников круглого стола, отметил: «Большинство решений в области качества данных, отслеживания, происхождения этих данных требуют ручного труда, остаются одномерными и не поддаются масштабированию. Автоматизация, машинное обучение, DataOps следующего поколения, обеспечение конфиденциальности, защиты данных сегодня имеют важнейшее значение не только для инноваций, но и для управления данными в будущем».
Представители Центра компетенций НТИ МГУ – руководитель направления IT и Data Science Роман Смирнов и руководитель направления правовых исследований и юридического сопровождения Игорь Терещенко – рассказали о недавних разработках Центра в области технологий обработки естественного языка (NLP) для распознавания документов и поделились, где эти разработки могут быть применены либо уже применяются.
По словам Романа Смирнова, команда Центра разработала решение, способное классифицировать и верифицировать документы на основе технологий NLP (включая BERT-модель) и графического распознавания. Совокупность этих технологий помогает машине классифицировать даже визуально неотличимые документы (например, устав организации, накладную, договор купли-продажи, договор аренды и т. д.). Верификация подразумевает проверку, соответствует ли документ определенным требованиями (например, содержит ли печати и подписи в необходимых местах). «Одно из наших достижений в части распознавания графических атрибутов – возможность отличать подпись от рукописного текста», – добавил Роман Смирнов.
«На входе у нас есть документ, мы извлекаем из него текст, анализируем его, понимаем, к какому классу нужно отнести этот документ (это устав/акт/приказ и т. д.), с помощью в том числе NER-технологии извлекаем определенные сущности и определяем, правильно ли, например, ИНН указан в документе…» – поделился Роман Смирнов.
Подобные технологии, в частности, дорабатывались командой Центра НТИ при решении задачи на хакатоне Audithon 2021 Счетной палаты РФ. В рамках конкурса была создана модель, способная извлекать из судебных актов следующие данные: ответчика, статью, по которой он привлечен к ответственности, год, приговор, регион, город и пр. «Этот результат в некотором смысле приближает нас к машиночитаемому праву, к возможности автоматизированной обработки судебных актов и извлечению некоторых значимых вещей», – обратил внимание Роман Смирнов. Анализ судебных актов может быть применен и для формирования качественной и достоверной статистики, добавил Игорь Терещенко.
Еще один из вариантов применения разработок в области распознавания документов – создание умного правового помощника для предпринимателей и граждан. «Это решение на этапе пилота, требует существенной доработки для реализации, но есть основа для него», – отметил Игорь Терещенко.
По его словам, такая умная программа на основании переписки с пользователем формирует простой и верный ответ на правовые вопросы. Алгоритм работы помощника предполагает, что сначала распознается входящий запрос, затем запрашивается необходимая информация (в том числе документы по определенному перечню с проверкой их содержания), после на основе полученных сведений автоматически формируется проект ответного документа с возможностью оценки правовых рисков.
Решение специалистов Центра НТИ апробировано на примере коммуникации Росреестра и предпринимателей, получивших от ведомства отказы или приостановления запросов. Определяя тему обращения предпринимателя, проверяя наличие отказа Росреестра и распознавая причины случившегося, сервис запрашивает и анализирует необходимые документы (как правило, они представлены в графическом формате), проверяет их комплектность и устанавливает наличие проблем, после чего формирует рекомендации по их устранению и автоматически заполняет заявление для повторного обращения в Росреестр.
В результате внедрения умного правового помощника в государственных органах станут возможны:
– Проверка документов на наличие типовых ошибок;
– Уменьшение риска возникновения нарушений законодательства и связанных с этим расходов;
– Повышение операционной эффективности до 80%;
– Снижение нагрузки на сотрудников, необходимость обработки вручную лишь нетиповых запросов;
– Обеспечение предпринимателей быстрой и квалифицированной поддержкой государства.
Игорь Терещенко также добавил, что при создании решений команда Центра НТИ ориентируется на то, чтобы они были масштабируемыми и могли применяться в разных организациях.
Доклад Анастасии Максимовой, доцента кафедры социологии знания Высшей школы современных социальных наук МГУ, был посвящен изучению социальной напряженности на основе анализа больших данных социальных медиа.
Максим Часовиков, соруководитель сообщества Digital&IT-директоров «яИТы», выступил с докладом «Анализ данных – текущее состояние и ожидания бизнеса».